
[bootcamp] Final Project 회고
카테고리: bootcamp
태그: bootcamp
🎯Final Project 들어가기에 앞서 - Day1
코드스테이츠에서 DevOps 부트캠프 과정을 시작한지 어느덧 4개월, 이제 수료까지 마지막 프로젝트만 남았다. 프로젝트의 각 팀은 4~5명의 팀원으로 이루어졌고 대략 2주 동안 진행될 예정이다. 우리 팀은 박xx님, 박xx님, 김xx님, 권xx님 4명으로 구성되었고 팀명은 각 팀원의 성을 따서 P2K2로 지었다. 오늘 한 일 중에 가장 힘든 일이었다. ㅎㅎ
시나리오: 고가용성 글로벌 팬 사이트
3티어 아키텍처로 구성된 커뮤니티를 운영하면서 K-Pop 팬들이 서로 소통할 수 있는 게시판을 운영하는 것이 목적입니다. 특정 팬덤의 확대로 사이트의 트래픽이 늘고 이에따라 운영 이슈도 더욱 많이 생기고 있습니다.
직면한 문제
- 글로벌 트래픽이 증가하였으며, 특정 국가의 이용자로부터 웹사이트 로딩이 느리다는 불만이 있습니다.
- 순간적으로 트래픽이 급증하는 형태를 보입니다. 종종 다운타임이 발생하기도 합니다.
- 모니터링 시스템의 부재
- dev/staging/production 환경이 분리되어 있지 않습니다.
요구 사항
- 서버 및 데이터베이스의 고가용성을 달성해야 합니다. 순간적인 트래픽 증가에 대응해야 합니다.
- 모니터링 시스템을 구축해야 합니다.
- CI/CD 파이프라인을 만들고 dev/staging/production 수준을 구분하고, 릴리즈 정책을 만듭니다.
- CRUD 기능을 포함한 간단한 3티어 REST API를 만들어야 합니다.
- 글로벌 트래픽 대응을 위한 방안을 제시해야합니다.
- 모든 서버는 컨테이너 환경에서 구현되어야 합니다.
🎯아키텍처 구성 - Day2-4
프로젝트 2일차부터 4일차까지 시나리오 요구사항에 필요한 리소스를 선택하고 취합하여 전체 아키텍처를 구상하였다. 이때 우리 팀이 가장 중점을 뒀던 부분은 시스템의 가용성과 확장성 그리고 AWS 리소스를 적절히 활용하여 구축 시간을 단축시키고 프로젝트 기간 내에 모든 구성을 완료하는 것이었다.
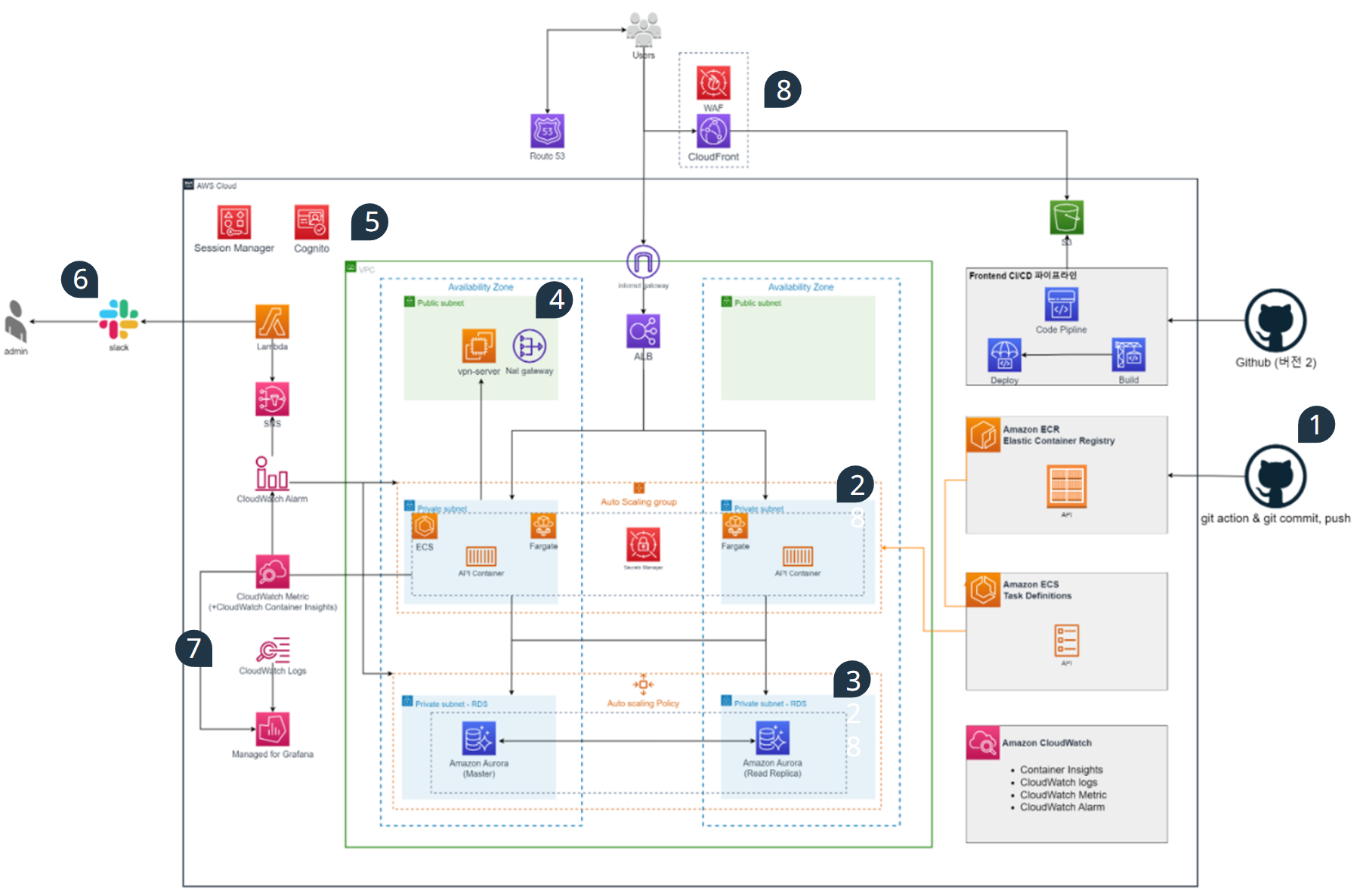
위 그림의 번호 순서대로 각각의 리소스가 하는 역할과 해당 리소스를 선택한 이유에 대해 간략히 설명하겠습니다.
- backend CI/CD 구현부로 github action을 이용하였으며 소스 리포지토리에 tag가 푸시되면 트리거됩니다. tag는 시맨틱 버전 규칙에 따라 작성하기로 약속했고 ECR 이미지 이름은 해당 tag의 이름으로 저장됩니다. 저장된 ECR 이미지는 새로운 TaskDefinition 개정을 생성하는데 사용되고 최종적으로 ECS Service가 새 개정을 참조하여 업데이트됩니다.
- api 서버가 구현되는 환경으로 ecs는 Multi AZ 기능과 auto scaling을 통한 높은 확장성 그리고 다른 컨테이너 오케스트레이션에 비해 간단한 구성과 운영이 가능하기 때문에 저희 서비스에 최적의 도구라고 생각하여 선택하게 되었습니다. 또한 Secret Manager를 통해 DB 엔드포인트에 대한 민감 정보를 암호화하여 저장하고 ECS Taskdefinition에서 평문 Value가 아닌 Value From으로 참조가 가능합니다.
- aurora는 스토리지 클러스터를 통한 스토리지 자동확장과 데이터 무결성을 보장하고 읽기 성능을 올렸으며, 쓰기 단순화를 통해 일반 RDS보다 쓰기 성능도 증가하였습니다. 무엇보다 자체적으로 autoscaling policy를 통해 컴퓨트 노드의 자동확장이 가능하고 Multi AZ를 지원하기 때문에 가용성도 확보할 수 있었습니다.
- Nat gateway는 프라이빗 서브넷에 위치한 ECS task 또는 Aurora 인스턴스에서 인터넷으로 향하는 Outbound 트래픽 경로를 열어주기 위해 사용되었고 일반적인 서비스 트래픽 처리에는 사용되지 않으나 DB 엔진 업데이트나 기타 외부와의 통신이 필요할 때 사용됩니다. 초기 NAT Gateway는 고강용성을 위해 Multi AZ로 구성하였으나 많은 비용이 발생했기에 1개 인스턴스로 축소하게 되었습니다. 또한 EC2 인스턴스에는 openVPN Access Sever가 구성이 되고 이는 개발자의 로컬 PC 환경이 VPC 안에 있는 것 처럼 동작하게 해줍니다. 우리 팀은 백엔드 코드 변경 시 Aurora와 연계하여 로컬에서 테스트가 필요했기 때문에 도입하게 되었습니다.
- Secret Manager는 EC2 서버에 웹 콘솔로 접속하고 연결된 세션에 대한 감사에 목적으로 구성하였습니다. 또 다른 장점으로 EC2 서버에 SSH 접속할 때 필요한 포트나 키를 관리할 필요가 없어집니다. Cognito는 애플리케이션에 회원가입, 로그인 하는데 필요한 사용자 데이터베이스로 사용하게 됩니다.
- CloudWatch에서 ECS를 모니터링 하다가 일정한 임계치를 초과하는 CPU 사용률이 감지되면 Alarm을 활성화하고 해당하는 event는 SNS로 보내집니다. SNS로 보내진 메시지는 Lambda 함수를 호출하게 됩니다. Lambda는 Slack 채널에 발생한 event를 필터링하여 전달합니다.
- CloudWatch Metrics과 Logs에 수집된 데이터를 소스로 Managed for Grafana 대시보드를 구성합니다. 대시보드에는 Aurora, ECS, WAF 등 다양한 Metircs과 Logs가 시각화합니다.
- 사용자는 Route53에서 DNS Lookup을 하고 CloudFront에 연결 요청합니다. CloudFront는 Frontend 페이지를 캐싱하고 WAF가 연결되어있어 다양한 webACL 규칙에 의거해 악의적인 패킷이 필터링됩니다. 또한 CloudFront 오리진은 S3 정적 웹사이트 호스팅 기능을 사용하였으며 프론트엔드 코드는 S3에 저장됩니다. AWS의 CodePipeline은 프로젝트 Github 리포지토리를 소스로 트리거됩니다.
🎯아키텍처 구현 - Day5-10
구성된 아키텍처를 실제 AWS Cloud에 구현하는 작업에 있어 크고 작은 트러블 슈팅 사례들이 있었습니다. 그 중에서 제가 겪고 기억에 남는 사례를 공유 드리겠습니다.
사례1: [ECR] InvalidSignatureException
에러메시지
ecr 레지스트리에 push 동작을 수행하기 전 login 과정에서 발생.
An error occurred (InvalidSignatureException) when calling the GetAuthorizationToken operation:
Signature expired: 20230304T133756Z is now earlier than 20230308T023955Z (20230308T025455Z - 15 min.)1.
Error: Cannot perform an interactive login from a non TTY device
문제 원인
aws cli는 GetAuthorizationToken 동작을 수행하는데 서명된 요청을 사용한다. 하지만 cli 명령을 사용한 시스템(로컬에서 virtualbox를 이용해 생성한 VM)의 시간이 동기화 되어 있지 않았고 요청에 사용된 자격증명은 만료된 것으로 계산되었다.
문제 해결
시스템 timezone 재 설정, ntp 데몬 설치 및 실행
sudo timedatectl set-timezone Asia/Seoul
sudo apt install ntp
sudo systemctl enable --now ntp
사례2: [ALB] Network Mapping
주의메시지
사용자의 api 요청이 ALB까지 도달하지 못하는 이슈 발생, ALB Network Mappring 탭에서 확인한 주의 메시지
The selected subnet does not have a route to an internet gateway. This means that your load balancer will not receive internet traffic.
You can proceed with this selection; however, for internet traffic to reach your load balancer, you must update the subnet’s route table in the VPC console
문제 원인
- ECS 서비스 생성과 함께 ALB를 생성하는 경우 ALB의 Network Mappings은 자동으로 ECS에서 사용 중인 서브넷으로 선택됨.
- 로드밸런서가 internet facing인 경우 Network Mappings는 퍼블릭 서브넷이어야 함.
- Network Mapping으로 프라이빗 서브넷이 선택된 경우 로드밸런서는 인터넷 트래픽을 수신할 수 없음.
- ECS와 함께 생성된 로드밸런서는 프라이빗 서브넷(ecs 서브넷)으로 Network Mapping이 설정됨. 따라서 인터넷 트래픽을 수신할 수 없음.
문제 해결
네트워크 매핑이 퍼블릿 서브넷을 가리키도록 변경. 매핑된 서브넷에는 네트워크 인터페이스가 각각 1개씩 생성되고 로드밸런서는 해당 인터페이스를 이용해 ecs task와 통신합니다
1. Amazon EC2 콘솔을 엽니다.
2. 탐색 창에서 Load Balancers를 선택합니다.
3. 로드 밸런서를 선택합니다.
4. 네트워크 매핑 탭에서 서브넷 편집을 선택합니다.
사례3: [S3] bucket policy
에러메시지
terraform에서 버킷 정책을 생성할 때 발생.
Error putting S3 policy: AccessDenied: Access Denied status code: 403
문제 원인
- “BlockPublicPolicy” 퍼블릭 액세스 차단이 활성화된 경우 퍼블릭 액세스를 허용하는 정책에 대한 PUT Bucket Policy 호출을 Amazon S3에서 거부함.
- 퍼블릭 액세스 차단을 모두 활성화하고 S3 버킷을 생성하면
- “s3:GetObject” action에 대한 principal이 “*”로 설정된 버킷 정책은 퍼블릭 액세스를 허용하는 정책 이므로 S3에서 PUT Bucket Policy 호출을 거부함.
문제 해결
CloudFront에 대한 s3 접근만 허용하도록 버킷 정책 수정
# aws_s3_bucket_public_access_block
resource "aws_s3_bucket_public_access_block" "s3_public_access" {
bucket = aws_s3_bucket.demo-tf-test-bucket.id
block_public_acls = true
block_public_policy = true
ignore_public_acls = true
restrict_public_buckets = true
}
#aws_s3_bucket_policy
resource "aws_s3_bucket_policy" "allow_access_from_another_account" {
bucket = aws_s3_bucket.demo-tf-test-bucket.id
policy = jsonencode({
"Version" : "2012-10-17",
"Statement" : {
"Sid" : "AllowCloudFrontServicePrincipalReadOnly",
"Effect" : "Allow",
"Principal" : {
"Service" : "cloudfront.amazonaws.com"
},
"Action" : "s3:GetObject",
"Resource" : "${aws_s3_bucket.demo-tf-test-bucket.arn}/*",
"Condition" : {
"StringEquals" : {
"AWS:SourceArn" : "${aws_cloudfront_distribution.s3_distribution.arn}"
}
}
}
})
}
사례4: [ECS] APP Auotoscaling
에러메시지
ECS appAutoscaling 관련 CloudWatch Alarm Event 수신 에러발생
"error": "No step adjustment found for metric value [99.83786010742188] and breach delta 49.837860107421875"
문제 원인
- “metric_interval_upper_bound” 값이 0인 경우 CloudWatch Alarm 에서 설정한 임계값과 같음
- “metric_interval_upper_bound” 값이 정의되지 않은 경우 +무한대의 값을 갖음
- “metric_interval_lower_bound” 값이 정의되지 않은 경우 -무한대의 값을 갖음
- scaleUp 정책에서 upper_bound 값이 0이고 lower_bound 값을 정의 하지 않았다면 스케일 동작이 수행되기 위한 지표의 사용량 범위 = -무한대 < 지표 < 임계값 이므로 임계값을 넘어 발생한 알림에 대해 스케일 동작을 수행할 수 없음
문제 해결
scale 정책에 대한 step_adjustment 값을 재조정
resource "aws_appautoscaling_policy" "ecs_scale_up_policy" {
name = "scale-up"
policy_type = "StepScaling"
resource_id = aws_appautoscaling_target.scale_target.resource_id
scalable_dimension = aws_appautoscaling_target.scale_target.scalable_dimension
service_namespace = aws_appautoscaling_target.scale_target.service_namespace
step_scaling_policy_configuration {
adjustment_type = "ChangeInCapacity"
cooldown = 60
metric_aggregation_type = "Maximum"
step_adjustment {
metric_interval_lower_bound = 0
metric_interval_upper_bound = 20
scaling_adjustment = 1
}
step_adjustment {
metric_interval_lower_bound = 20
scaling_adjustment = 2
}
}
}
resource "aws_appautoscaling_policy" "ecs_scale_down_policy" {
name = "scale-down"
policy_type = "StepScaling"
resource_id = aws_appautoscaling_target.scale_target.resource_id
scalable_dimension = aws_appautoscaling_target.scale_target.scalable_dimension
service_namespace = aws_appautoscaling_target.scale_target.service_namespace
step_scaling_policy_configuration {
adjustment_type = "ChangeInCapacity"
cooldown = 60
metric_aggregation_type = "Maximum"
step_adjustment {
metric_interval_lower_bound = -20
metric_interval_upper_bound = 0
scaling_adjustment = -1
}
step_adjustment {
metric_interval_upper_bound = -20
scaling_adjustment = -2
}
}
}
사례5: [openVPN] Client 연결 오류
로그
openVPN Client 프로그램에서 Access Server에 연결할 때 Timeout 에러가 발생
WinCommandAgent: transmitting bypass route to 172.16.1.84
{
"host" : "172.16.1.84",
"ipv6" : false
}
문제 원인
- openVPN 서버는 테라폼 코드가 apply될 때마다 재배포됨
- openVPN 서버 설치 마법사 실행 시 VPN Server Hostname을 지정하지 않으면 프라이빗 IP로 지정됨.
- 사용자가 openVPN 클라이언트 프로그램을 설치하면 해당 프로그램은 openVPN 서버 host를 프라이빗 IP로 설정함.
- 클라이언트 프로그램에서 프라이빗 IP로 접속을 시도하기 때문에 타임아웃 발생 (클라이언트 프로그램에서 서버 프로필을 변경하여도 반영되지 않음)
문제 해결
- openVPN admin 페이지의 Server Network Settings 탭에서 VPN Server Hostname을 탄련적 IP 또는 도메인 이름으로 변경해준다.

- openVPN admin 페이지에서 Access Server를 업데이트하고 다시 시작한다.
- openVPN Client 프로그램을 삭제하고 재 설치한다.
🔎시연
(…)
🎯추후 개선방향성
| AS-IS | 항목 | TO-BE |
|---|---|---|
| - 모든 IAM 사용자는 관리자 권한을 갖음 - aws 액세스키를 사용하고 있고 적절히 만료되지 않음 - 리소스 기반 정책에 불필요한 권한이 있음 |
보안 | - 최소 권한 부여 원칙에 따라 각 사용자 및 서비스별 접근 권한을 부여 - 액세스키 대신 IAM Role을 사용하여 임시 자격증명 부여 |
| - 테라폼 리소스간 심한 의존성 결합 문제 - dev/staging/production 환경이 분리되지 않음 - 환경에 따른 배포 프로세스가 마련되지 않음 |
환경 분리 |
- 우선순위를 정하고 각 리소스별 추상화해서 모듈화 또는 따로 관리 - 환경에 맞는 배포 기준을 정하고 릴리즈, 태그, 브랜치를 격리하여 체계적으로 관리 |
| - cloudwatch에서 제공하는 메트릭 외에 다른 지표를 제공하지 못함 - 제한된 기능의 경고 알림 시스템 - 임계치 설정을 위한 기준이 마련되지 않음 |
모니터링 | - 필요한 사용자 정의 지표를 수집하기 위한 모니터링 시스템 도입 - 별도의 경고 알림 시스템 구축 - 기존 데이터 및 SLO, SLI 기준에 따라 임계치 설정 |
| - ecs, ec2, rds와 같은 리소스 사용량에 비해 적절한 스펙이 프로비저닝 되었는지 판단하기 어려움 - 구체적인 가용성, 확장성, 성능 기준이 마련되지 않음 |
비용 | - 서비스 모니터링을 통해 리소스 사용량 추이를 파악하고 적절한 스펙을 할당 - 고객과의 지속적인 커뮤니케이션을 통해 요구사항을 구체화하고 필요한 리소스와 불필요한 리소스를 선별 |
😀후기
(…)
👍 개인 공부 기록용 블로그입니다. 오류나 조언이 있으시면 언제든지 댓글 혹은 메일로 남겨주시면 감사하겠습니다! 😄
댓글남기기